파운데이션 모델(Foundation Model)과 생성모델(Generative Model)의 차이
Diffusion Model 에 대해서 이야기 하다가
Foundation Model = Generative Model 로 생각하는 사람들이 있어서 정리해본다.
Foundation 모델의 정의에 대해서는 다음의 논문을 참조하였다.
[1] https://arxiv.org/abs/2108.07258
On the Opportunities and Risks of Foundation Models
AI is undergoing a paradigm shift with the rise of models (e.g., BERT, DALL-E, GPT-3) that are trained on broad data at scale and are adaptable to a wide range of downstream tasks. We call these models foundation models to underscore their critically centr
arxiv.org
[1]을 인용하면 정리하면 다음과 같다.

파운데이션 모델
- 데이터 : 광범위한 대규모 데이터 활용 (Text, Images, ...)
- 학습방식: 일반적으로 자가 학습(self-supervision)
- 적용: 미세조정(fine-tunned)을 통해 다운스트림 작업(downstream tasks)에 사용가능(adaptation)
- 예: BERT [Devlin et al. 2019], GPT-3 [Brown 외. 2020], CLIP [Radford 외. 2021]
아래의 그림을 보면 더욱 직관적으로 이해 가능하다.
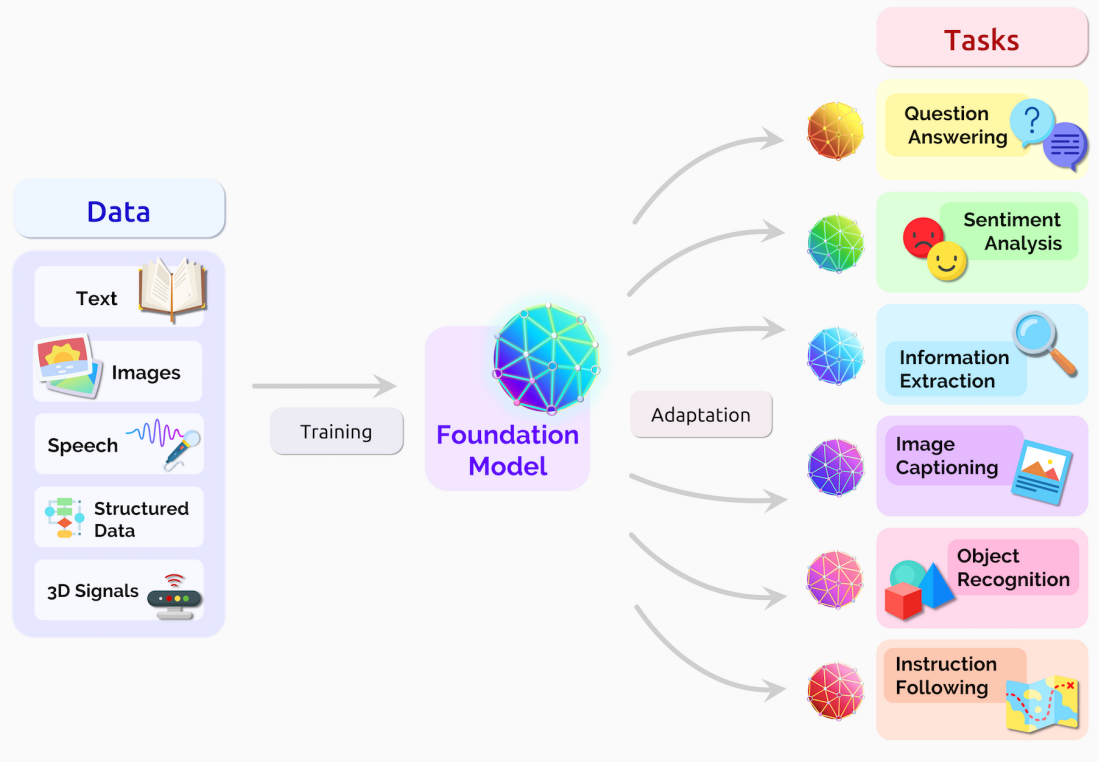
다만, NLP에서 생성모델 등을 통해 놀라운 결과들을 보여주었기 때문에 파운데이션 모델 = 생성모델로 보는 것이 아닌가 싶다.
생성모델은 아래와 같이 주어진 데이터의 확률 분포를 학습하는 것이 목적이다.
따라서, 잘 학습되었을 경우 주어진 데이터와 유사한 데이터를 생성해낼 수 있다!
그렇기 때문에 대규모의 데이터를 가지고 학습하였고, 생성모델의 성능이 좋을 경우,
AI 가 생성한 데이터가 주어진 데이터와 차이가 없게 느껴질 경우가 있는 것이다.
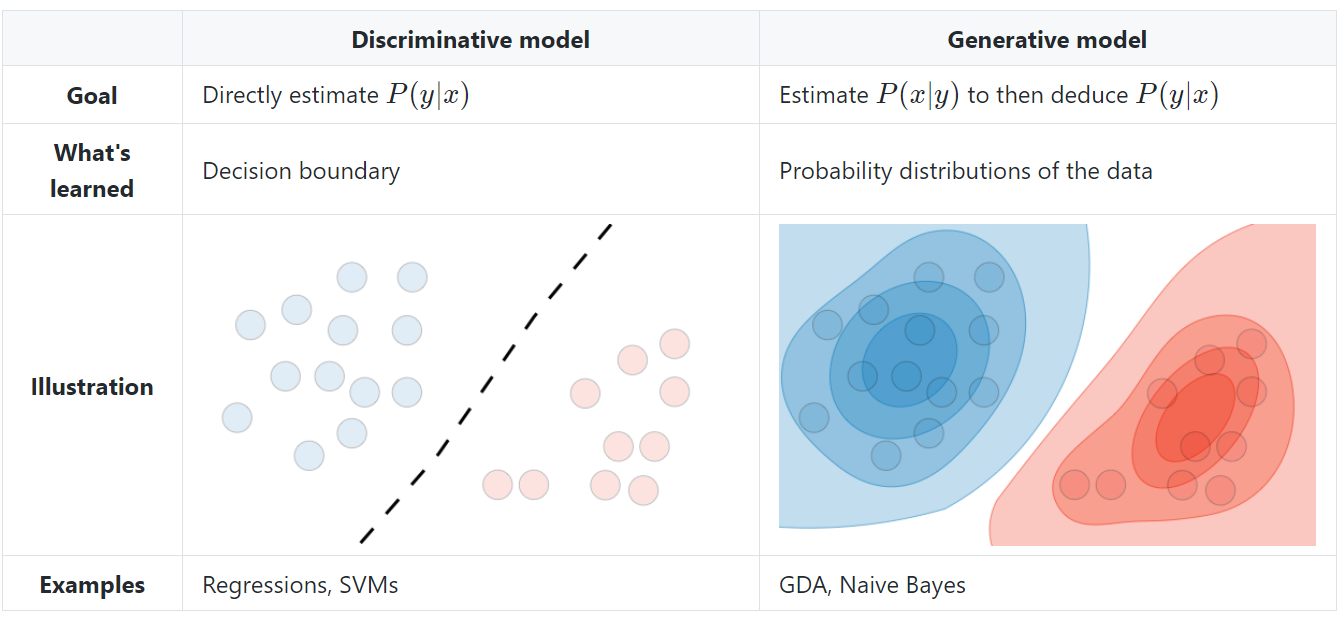
파운데이션 모델이 주로 생성모델을 활용하지만
그 본연의 의미는 다르다고 생각해야 할 것 같다.