-
https://arxiv.org/abs/2108.07258
On the Opportunities and Risks of Foundation Models
AI is undergoing a paradigm shift with the rise of models (e.g., BERT, DALL-E, GPT-3) that are trained on broad data at scale and are adaptable to a wide range of downstream tasks. We call these models foundation models to underscore their critically centr
arxiv.org
저자수도 엄청나고 페이지 수도 무려 214페이지(!)나 된다.
현재 구글 스칼라 기준으로는 1420회의 인용수를 기록하고 있다.
본 글에서는 기회보다는 위험성에 초점을 맞춰서 정리해보고자 한다. (기계번역의 도움을 받아)
페이지로 따지자면 101~123 정도가 될 것 같다.

4.6 Data
4.6.1 Data Management Desiderata.
(1) 확장성(Scalability)
파운데이션 모델은 점점 더 방대한 양의 데이터에 대해 학습되고 있음. 우다오 2.0 모델은 4.9TB의 멀티모달 데이터에 대해 학습되고 있는 중. 이 규모는 더 커질 것으로 예상됨. 멀티모달 파운데이션 모델 데이터를 처리할 수 있는 확장성이 뛰어난 기술에 대한 필요성이 점점 더 커지고 있음.
(2) 데이터 통합(Data integration)
파운데이션 모델을 사용한 최근의 연구는 통합된 정형 및 비정형 데이터를 활용하면 모델이 희귀한 개념을 더 잘 일반화하고 사실적 지식 리콜(factual knowledge recall)을 개선하는 데 도움이 될 수 있음을 보여줌. 하지만, 파운데이션 모델에 대한 데이터셋을 통합하는 것은 여전히 어려운 과제임. 다양한 모달리티와 여러 도메인에 적용할 수 있는 데이터 통합 솔루션이 필요함.
(3) 개인정보 보호 및 거버넌스 통제(Privacy and governance controls)
파운데이션 모델에 사용되는 학습 데이터는 데이터 주체의 개인정보를 침해할 위험이 있음. 즉, 데이터 주체의 동의 없이 또는 원래 동의가 이루어진 맥락을 벗어나 데이터를 공개, 수집 또는 사용할 수 있음. 웹 크롤링 데이터의 관리 및 저작권에 대한 법적 문제가 여전히 남아 있기 때문에 웹 데이터 사용의 결과는 공공 및 민간 부문의 기초 모델 제공자에게는 여전히 불분명함. 안전하고 책임감 있는 데이터 관리를 보장하기 위해 파운데이션 모델 제공자가 새로운 규정과 지침에 적응할 수 있도록 지원하는 도구가 필요.
(4) Privacy and governance controls 생략
(5) 데이터 품질에 대한 이해(Understanding data quality)
데이터 품질은 모델 성능에 영향을 미치지만, 학습 데이터와 관련 데이터 서브셋(subsets)을 체계적이고 확장 가능하게 이해하기 위한 툴킷이나 방법은 아직 초기 단계임. 데이터 생성 프로세스는 복잡할 수 있으며, 데이터에는 다양한 유형의 편향(biases)이 포함될 수 있고, 오염되거나 허위 또는 중복된 정보로 구성될 수 있음. 데이터는 또한 지속적으로 업데이트되고 개선되며 새로운 엔티티, 분포 변화(distribution shift), 개념 의미 변화(concept meaning shift)가 있을 있음 또한, 일단 배포된 파운데이션 모델은 세분화된 데이터 서브집단(fine-grained sub-population)에 대해 바람직하지 않은 동작을 나타낼 수 있음. 파운데이션 모델 제공업체는 이를 감지하고 완화해야 함. 다양한 유형의 바람직하지 않은 데이터를 감지하고 잠재적으로 완화할 수 있는 툴킷이 필요. 대화형 반복 방식으로 모델 성능을 개선할 수 있고, 훈련 데이터의 동적 특성에 적응할 수 있는 툴킷이 필요.
4.6.2 Data Hub Solution. 생략
4.7 Security and privacy

4.7.1 위험요소들(Risks)
(1) Single points of failure. 생략
(2) 데이터 오염(Data poisoning)
지금까지 파운데이션 모델은 웹에서 스크랩한 대규모의 큐레이션되지 않은 데이터 세트를 기반으로 학습됨. 이러한 데이터 수집은 파운데이션 모델의 훈련 데이터에 대한 포이즈닝 공격(예: 특정 개인이나 회사를 겨냥한 혐오 발언을 Reddit의 아웃바운드 페이지 몇 개에 주입)을 용이하게 함. 더 나쁜 것은 오늘날 모델의 규모와 정확도가 증가함에 따라 포이즈닝 공격의 위력이 더욱 악화될 수 있다는 점임. 예를 들어, Github 데이터에 대해 GPT-2로 학습된 코드 자동 완성 시스템이 몇 개의 악성 파일만 삽입해도 안전하지 않은 코드 스니펫을 제안하도록 포이즈닝될 수 있음을 보여줌. 또한 칼리니와 테르지스는 CLIP 스타일 모델에 대한 표적 공격은 300만 개의 훈련 예제 중 단 2개만 수정하면 된다는 것을 보여줌.
(3) Function creep & dual use. 생략
(4) 멀티모달 불일치성(Multimodal inconsistencies)
멀티모달리티(multimodality)는 공격자가 여러 모달리티 간의 불일치를 악용할 수 있게 함(exploit inconsistencies across modalities)으로써 파운데이션 모델의 공격 지점들을을 증가시킬 수 있음. 이러한 공격의 가능성은 '아이팟'이라는 단어가 붙어 있는 사과를 아이팟으로 분류하는 CLIP의 유명한 사례에서 입증된 바 있음. 보다 일반적으로, 하나의 개념이 서로 다른 양식을 사용하여 표현될 수 있는 경우, 이러한 양식 간의 불일치가 악용될 수 있음. 이러한 불일치는 학습된 양식 중 하나에만 주로 의존하는 작업에 파운데이션 모델을 적용할 때 특히 우려됨. 예를 들어 CLIP에서 추출한 특징을 얼굴 인식에 사용하는 경우, 이 작업은 순전히 시각적인 작업이지만, 적응된 모델의 기능은 여전히 텍스트 신호에 민감함(따라서 공격자는 얼굴이 새겨진 옷을 입음으로써 얼굴 인식을 회피할 수 있음.) 또는 자율 주행 시스템(주로 시각에 의존하는 애플리케이션)이 "녹색"이라는 단어가 적힌 광고판을 보고 이를 녹색 신호등으로 잘못 해석하는 자율주행 시스템을 생각해볼 수 있음.
4.7.2 기회 요소들(Opportunities) 생략
(1) Security choke points. 생략
(2) Cheaper private learning. 생략
(3) Robustness to adversarial examples at scale
적대적 예제(adversarial examples)에 대해 강력한 모델을 훈련하려면 일반적인 훈련에 비해 훨씬 더 많은 데이터가 필요하지만, 라벨이 지정되지 않은 데이터로도 이 격차를 해소할 수 있다는 증거가 있음. 또한 일부 환경에서는 모델 크기와 용량을 늘리는 것(즉, 파라미터를 과도하게 설정하는 것)이 적대적 강건성(adversarial robustness)을 달성하는 데 필요한 것으로 나타났음. 과도한 매개변수화(over-parameterization)와 라벨링되지 않은 데이터를 활용하여 적대적 강건성을 달성하는 가장 좋은 방법을 이해하는 것은 향후 연구의 중요한 방향임. 모델 규모와 훈련 세트 규모 측면에서 전례 없는 규모를 고려할 때, 파운데이션 모델은 이러한 연구의 혜택을 누릴 수 있는 독보적인 위치에 있음. 그러나, 현재의 파운데이션 모델은 안타깝게도 최악의 적대적 교란상황(worst-case adversarial perturbations)에 대한 강건성이 거의 향상되지 않았음. 그러나 CLIP과 같은 다중모형 모델은 (적대적이지 않은) 분포 변화(distributional shift)에 대해 놀라울 정도로 견고함. 이러한 분포 강건성의 향상이 실제 공격에 대한 복원력 향상으로 이어질 수 있는지는 또 다른 흥미로운 미해결 과제임. 특히 공격자가 다양한 제약(예: 제한된 쿼리 액세스 또는 계산 예산)을 받는 환경에서, 기본 모델이 최악의 '화이트박스' 공격(worst-case white-box attack)에 취약한 상태로 남아 있더라도 개선된 분포 강건성은(enhanced distributional robustness) 전반적인 보안 향상으로 이어진다는 낙관적 이유가 있음.
4.8 분포 변화에 대한 강건성(Robustness to distribution shifts)

4.8.1 Advantages 생략
4.8.2 Persistent challenges(1) 허위 상관관계 (Spurious correlations)
허위 상관관계(Spurious correlations)는 훈련 분포에서는 예측력이 있지만 테스트 분포에서는 예측력이 없는 피처와 레이블 간의 통계적 상관관계임. 잘 알려진 예로는 물체 인식을 위한 배경색 의존도, 의료 진단을 위한 수술 마커 의료 진단, 크라우드소싱 데이터의 주석자 편향성, 인구통계학적 편향성 등이 있음. 모델이 이러한 허위 상관관계를 학습하는 이유는 크게 파운데이션 모델 학습 및 적응 데이터에서 이러한 편향이 있으며, 이 문제는 단순히 더 큰 모델로 해결할 수 없기 때문.
(2) 외삽 및 일시적 변화 (Extrapolation and temporal drift)
파운데이션 모델의 퓨샷 및 제로 샷 기능은 이러한 모델이 훈련 분포를 외에 점점 더 많이 사용된다는 것을 의미. 대규모 파운데이션 모델 학습은 새로운 분포에 대한 특정 형태의 외삽에 도움이 될 수 있지만, 외삽 기능에는 한계가 있을 수 있음. 예를 들어, 기존 언어 모델은 재학습 없이는 세계 지식의 변화나 언어 변경을 처리할 수 없고, CLIP의 제로 샷 전이(zero-shot transfer)는 위성 이미지 영역에서 큰 어려움을 겪으며, ImageNet 사전 학습은 의료 이미지에서 대규모 모델의 성능을 크게 향상시키지 못함. 우리는 파운데이션 모델이 주어진 모달리티(예: 모든 이미지) 내에서 자동으로 추정한다고 가정할 수 없으며, 파운데이션 모델에 의해 새로 활성화되는 추정 형태와 접근할 수 없는 형태를 정의하고 분리하는 것이 점점 더 중요해질 것이라고 생각함. 분포 변화(distribution shifts)에 대한 기존의 분류법이 일반적으로 제안되어 왔지만, 파운데이션 모델이 효과적인 분포 변화 유형을 완전히 이해하고 정의하는 것은 신뢰성 연구의 주요 미해결 문제.
4.8.3 Opportunities. 생략
Understanding foundation model representations. 생략
Data augmentation in foundation model training. 생략
Encoding structure in foundation model training. 생략
Specialization vs. diversity in foundation model training data. 생략
Adaptation methods. 생략
4.9 AI safety and alignment
4.9.1 Traditional problems in AI safety. 생략
4.9.2 현재 파운데이션 모델 및 AI 안전성(Current foundation models and AI safety)
(전략) 한 가지 문제는 파운데이션 모델의 훈련 목표와 원하는 행동 사이의 불일치임. 예를 들어, 언어 모델은 진실성에 관계없이 훈련 말뭉치에 있는 모든 문서의 다음 단어를 예측하도록 훈련될 수 있지만 사용자는 모델이 진실하거나 유용한 텍스트만 출력하기를 원할 수 있음. 목표 지향 에이전트를 원하는 행동으로 유도하는 한 가지 잠재적인 방법은 행동에 대한 자연어 설명으로 에이전트를 훈련시키는 것. 이렇게 하면 언어를 통해 에이전트를 유도할 수 있을 뿐만 아니라 제어 가능한 생성 및 소스 어트리뷰션 방법과 유사하게 에이전트가 '믿고 있는' 작업을 설명하는 해석 가능한 언어를 출력할 수 있게 될 수 있음. 그러나 실제 이러한 모델의 신뢰성과 자기 일관성을 보장하고, 이러한 모델이 어떻게 작동하는지에 대한 보다 기계적인 이해를 얻기 위해서는 추가적인 발전이 필요. 또한 자연어 기반의 미래 기반 모델 제어를 통해 더 나은 작업 지정 및 모니터링이 가능해지더라도, 모델이 인간으로부터 기만적이거나 다른 방식으로 바람직하지 않은 행동을 습득할 수 있음. 이러한 동작을 식별하고 무력화하는 것은 향후 연구의 또 다른 중요한 방향.
4.9.3 미래 파운데이션 모델에서 발생할 수 있는 잠재 재앙적 위험요소들 (Potential catastrophic risks from future foundation models)
(1) 재앙적 강건성 오류 (Catastrophic robustness failures)
새로운 종류의 데이터에 직면했을 때 모델이 예기치 않거나 해로운 방식으로 작동할 수 있음. 이러한 실패는 파운데이션 모델이 다양한 작업과 상황에 빠르게 적응하는 파운데이션 모델의 기능을 활용하는 중요한 시스템에 통합된 경우 특히 치명적일 수 있음. 전쟁 시스템(원치 않는 무기 사용으로 분쟁을 촉발할 수 있음), 중요 인프라(중요한 에너지 또는 농업 기능의 우발적 파괴) 또는 경제 활동의 상당 부분에 필수적인 시스템(예기치 않은 실패로 인해 생활 수준이 갑자기 붕괴되고 정치적 불안정을 초래할 수 있음)에서 실패가 발생할 경우 치명적일 수 있음. 실제로 치명적인 신뢰성 오류의 위협은 다른 종류의 AI와 달리 파운데이션 모델에 관련이 있음. 왜냐하면 파운데이션 모델은 다양한 사용 사례에 맞게 조정될 수 있는 단일 모델로 구성되어 있기 때문임. 다양한 사용 사례에 적용될 수 있는 단일 모델로 구성되어 있기 때문에, 모델이 학습한 통계적 연관성에서 파생된 신뢰성 오류는 원칙적으로 여러 다른 도메인에 걸쳐 상호 연관된 방식으로 나타날 수 있음. 동일한 파운데이션 모델이 여러 중요 기능에 통합된 경우, 모델의 견고성이 부족하면 여러 중요 기능 또는 안전장치에 걸쳐 상호 연관된 장애가 발생할 수 있음.
(2) Misspecified goals 생략4.10 이론(Theory). 생략
4.11 해석가능성(Interpretability)
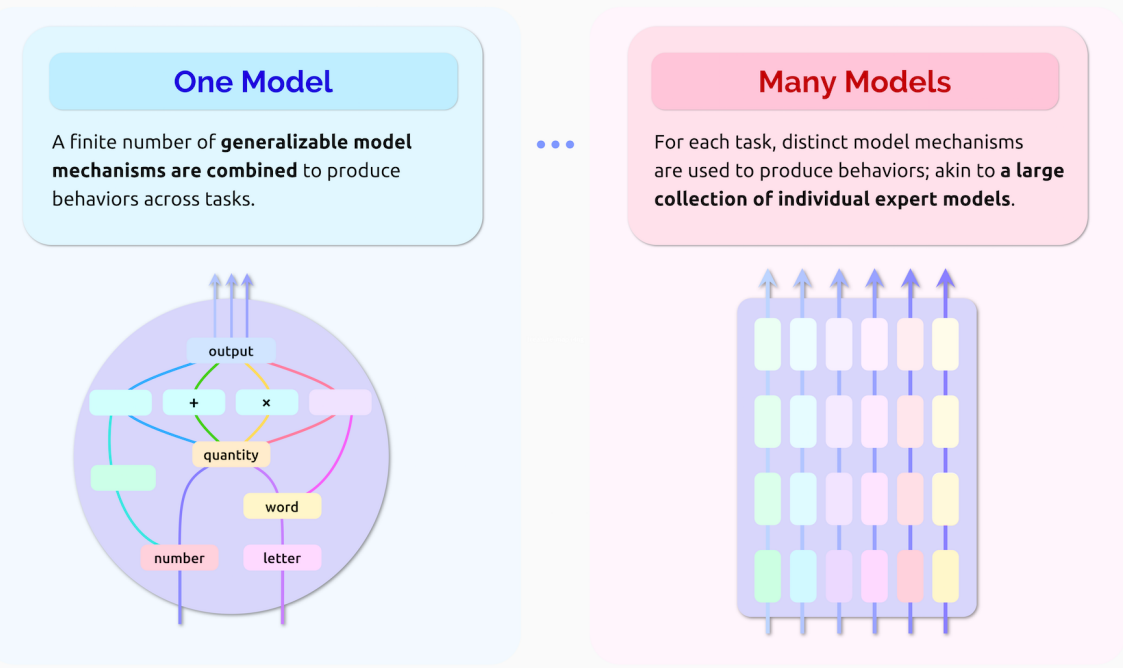
대부분의 다른 머신러닝 모델과 비교했을 때, 파운데이션 모델은 학습 데이터와 복잡성이 방대하게 증가하고 예상치 못한 기능이 등장한다는 특징이 있음. 파운데이션 모델은 예상치 못한 작업을 수행할 수 있고 이러한 작업을 예상치 못한 방식으로 수행할 수 있음. 따라서 파운데이션 모델의 채택이 증가함에 따라 이들의 행동을 이해하고자 하는 욕구와 요구가 증가.
작업에 특화된 모델(task-specific models)과 달리, 파운데이션 모델은 방대하고 일반적으로 매우 이질적인 데이터 세트에 걸쳐 훈련되며, 잠재적으로 여러 도메인과 양식에 걸쳐 있음. 이러한 학습을 통해 파운데이션 모델은 다양한 유형의 다운스트림 작업에 적응하고 각 작업에 특정한 행동을 보이는 능력에서 알 수 있듯이 작업과 도메인에 따라 크게 달라질 수 있는 매우 광범위한 행동을 학습함.
텍스트의 다음 단어를 단순히 예측하기 위해 하나의 거대한 모델로 훈련된 GPT-3를 예를 들어봄. 이는 매우 구체적이고 정의하기 쉬운 학습 작업이지만, 모든 종류의 인터넷 텍스트로 구성된 방대한 학습 데이터 세트와 결합함으로써 GPT-3는 다음 단어 예측과 관련된 기능을 훨씬 능가하는 기능을 확보할 수 있었음. 그 결과, GPT-3는 이제 몇 가지 훈련 샘플만 제공되면 간단한 산술이나 컴퓨터 프로그래밍과 같이 원래의 훈련 작업 범위를 벗어난 행동도 적응할 수 있게 되었음. 이는 파운데이션 모델에 대한 가장 단순해 보이는 질문인 '어떤 기능을 가지고 있는가'라는 질문에 답하는 것조차 어렵다는 것을 보여줌. 또한 이러한 다양한 기능이 모델 내의 알고리즘 빌딩 블록과 같은 별개의 모델 메커니즘에 어느 정도 의존하는지는 아직 밝혀지지 않은 문제임.
한편, 파운데이션 모델은 여러 작업과 도메인에서 잘 수행하기 위해 일반화 가능한 모델 메커니즘을 활용하는 단일 모델로 해석할 수 있음. 이 경우 이러한 메커니즘을 식별하고 특성화함으로써 그 행동을 완전히 이해할 수 있음. 반면에, 파운데이션 모델이 서로 다른 작업에 대해 심오하게 구별되는 동작을 적용하는 능력은 각각 특정 작업에 맞게 조정된 독립적인 전문가 모델의 대규모 모음으로 이해할 수도 있음을 시사함. 예를 들어, GPT-3가 산술을 수행하는 데 사용하는 모델 매개변수가 영어에서 프랑스어로 번역하는 데 사용되는 매개변수와 큰 관련이 있을 것 같지는 않음. 따라서 이 경우 한 작업의 모델 동작에 대한 설명이 다른 작업의 동작에 대한 정보를 반드시 제공하는 것은 아님. 우리는 이를 파운데이션 모델의 단일모델- 다중모델 특성(위 그림 참조)이라고 부름. 파운데이션 모델이 하나의 모델과 여러 모델 사이의 스펙트럼에서 어디에 위치하는지 이해하는 것이 그 행동을 이해하는 데 핵심이 될 것이라고 주장함. 이 연구 분야를 체계화하기 위해, 우리는 먼저 모델이 무엇을 할 수 있는지, 왜 특정 행동을 산출하는지, 마지막으로 어떻게 산출하는지 이해하는 데 있어 도전과 기회를 논의하는 세 가지 수준의 파운데이션 모델을 제시하고 논의함. 구체적으로, '무엇'에 대한 질문은 모델 내부를 들여다보지 않고도 모델이 수행할 수 있는 행동의 종류를 특성화하는 것을 목표로 하며, '왜'에 대한 질문은 모델의 행동에 대한 설명을 제공하는 것을 목표로 함.
4.11.1 Characterizing behavior. 생략
4.11.2 Explaining behavior. 생략
4.11.3 Characterizing model mechanisms. 생략4.11.4 해석불가능성과 해석가능성의 영향(Impacts of non-interpretability and interpretability)
파운데이션 모델의 광범위한 채택은 최근 많은 학제 간 연구자들이 중요한 의사결정에 복잡한 블랙박스 모델을 사용하지 말고 본질적으로 해석 가능한 모델의 오랜 개발과 적용에 집중하자는 주장과 상충된다는 점을 강조하고 싶음. 이러한 어려움 속에서 파운데이션 모델을 해석하는 작업은 양날의 같음. 대규모 머신러닝 모델, 그리고 현재 파운데이션 모델은 대부분 강력한 기업과 기관에서 배포하는 경우가 많으며, 해석 가능성의 점진적인 발전이 '윤리 세척'을 위해 과장되어 마치 해석 가능성을 달성한 것처럼 모델을 계속 사용할 가능성이 있음. 이는 알고리즘 해석 가능성의 기존 표준에 훨씬 못 미치는 현실을 무시한 것임. 게다가 해석가능성에 대한 접근 방식이 모델과 그 구현 및 매개변수에 대한 쉬운 접근을 전제로 할 때, 해석가능성은 강력한 기관을 보호하는 역할을 할 뿐만 아니라 모델 지식을 한 손에 집중시키는 역할을 할수 있음.
파운데이션 모델의 해석 가능성을 위해 노력하는 사람들에게는 연구자와 모델 소유자만 해석 가능한 파운데이션 모델을 만들기 위해 노력하고 있는지, 아니면 모든 사람이 해석 가능한 파운데이션 모델을 만들기 위해 노력하고 있는지 지속적으로 질문해야 할 책임이 있음. 동시에, 파운데이션 모델이 이미 배포되고 있는 한, 해석 가능성에 대한 작업은 파운데이션 모델에 대한 지식을 전환하고, 따라서 데이터화되고 평가된 사람들에게 힘을 실어줄 수 있는 독특한 기회를 제공하며, 해석은 모델의 사회적으로 두드러진 측면을 발견할 수 있도록 촉진할 수 있음. 보다 근본적으로, 누구나 파운데이션 모델의 행동을 해석할 수 있는 접근 가능한 방법을 만드는 작업은 다양한 사람들에게 권력을 이동시켜 모델을 조사할 기회, 개인이나 커뮤니티에 중요한 모델의 측면을 발견할 기회, 파운데이션 모델 사용에 의미 있게 동의하거나 개선하거나 완전히 이의를 제기할 기회를 창출함. 마지막으로, 연구자들은 파운데이션 모델의 해석 가능성을 목표가 아닌 질문으로 바라보는 것이 중요함. 연구를 통해 파운데이션 모델의 해석 가능성 부족이 본질적인 문제인지, 이러한 시스템의 사용(또는 규제 강화)을 방해하는 심각한 문제로 깊이 연구하고 널리 알려야 하는지, 아니면 미래의 파운데이션 모델이 모두를 위한 높은 수준의 해석 가능성을 유지할 수 있는지 여부를 탐구하고 평가할 수 있음.